







一个卷积神经网络的基本构成一般有卷积层(convolutional layer)、池化层(pooling layer)、全连接层(fully connection layer)。本文以caffe中的LeNet-5为例,分析卷积层和全连接层的参数数量和计算量情况。
卷积层的基本原理就是图像的二维卷积,即将一个二维卷积模板先翻转(旋转180°),再以步长stride进行滑动,滑动一次则进行一次模板内的对应相乘求和作为卷积后的值。在CNN的卷积层中,首先是卷积层维度提升到三维、四维,与二维图分别进行卷积,然后合并,这里的卷积一般是相关操作,即不做翻转。具体如下图所示:
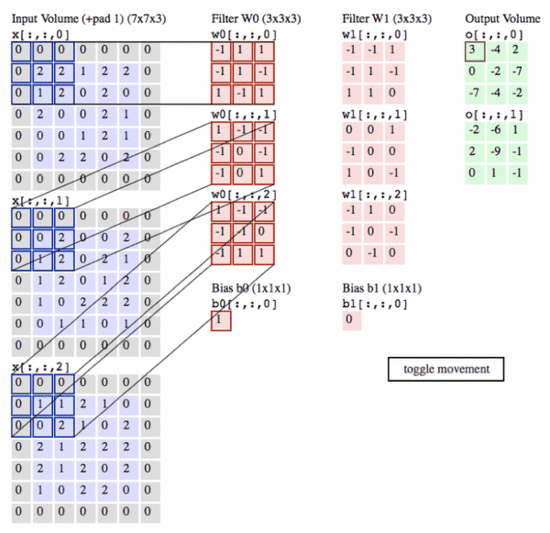
上图中左边的一幅输入图的三个通道,中间是卷积层,尺寸为3*3*3*2,这里就是三维卷积,得到的特征图还是一个通道,有两个三维卷积得到两个featuremap。
我们以caffe中的LeNet-5的lenet.prototxt为例。
一、卷积层
name: "LeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 64 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler { 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









